

Experiment: 10 million requests in Python
An experiment on concurrency in Python and a prequel to 10 million requests in Scala

This is part of a 2-part series on launching concurrent HTTP requests.
See this later post on doing the same in Scala.
Subjectivity notice:
This is an experiment I conducted with limited time and effort. This is not a full-scale rigorous study. There might be details that I might have missed.
Motivations
Concurrency is a powerful concept in programming that seeks to maximise the use of compute resources by handing control over to other tasks while waiting for IO-bound tasks to complete.
I had wanted a project to try out the concurrency concepts I recently learnt in courses on Scala’s Cats Effect and fs2 when I got reminded of a blog post by Pawel Miech I read a long time ago on launching 1 million requests using asyncio and aiohttp. It was a perfect use case for me.
So I decided to first reproduce Pawel Miech’s post (with a bit of modification from another blog post by Cristian Garcia) with the aim of understanding the parameters behind running the “1 million request” experiment before trying it myself in Scala.
The code is basically from the aforementioned blog posts. You can find it in this repo.
Experiment Parameters
I will be running a HTTP server that returns a simple message after some random delay of n seconds for each request. The aim is to launch r requests via client program in the shortest amount of time.
The experiment is split into two phases.
A testing phase, where I run the server and client using diferent parameters to understand how the duration to launch all requests is affected
A final phase, where I run 10 million requests using the optimal parameters.
In the first phase, there are 3 main parameters that can be tested.
The duration that each request takes. In this case, I tried a request duration uniformly distributed betwen 0 and 3s (like in Pawek Miech’s blog post).
The total number of requests to be launchced, r = 1000, 3000, 10000, 30000, 100000, 300000
The number of concurrent connections, s, that can be made, controlled by a semaphore. I tried s = 1000, 2000, 4000, 6000, 8000, 10000
Results
Phase 1: Parameter tuning
The figures below show the results in number of requests per minute against the total number of requests made, r.
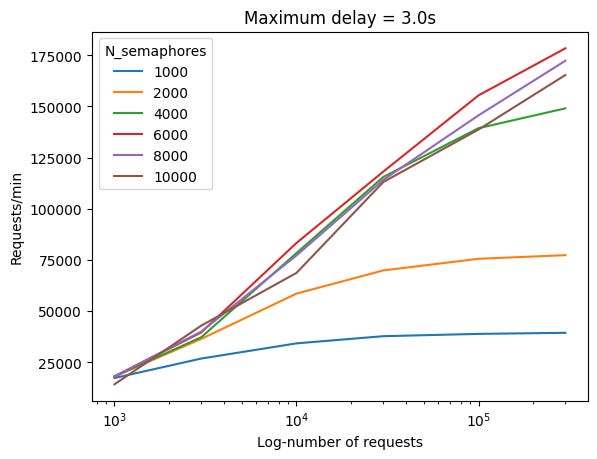
The first thing to note is that the time it took to launch all the requests asynchrounously is definitely much faster than sequentially. For example, it took around 3.5s to launch 1000 requests. Assuming an average duration of 1.5s per request, 1000 requests would have taken ~1500s to launch sequentially!
With s=1000 and 2000, the request per min saturates as the number of requests increases. This is because there are only so many concurrent requests that can be made. But as the number of concurrent requests allowed increases, we are able to launch more connections concurrently thus allowing us to increase the rate of requests.
Note that the x-axis is in log-scale. So what looks like a straight line is actually a concave line.
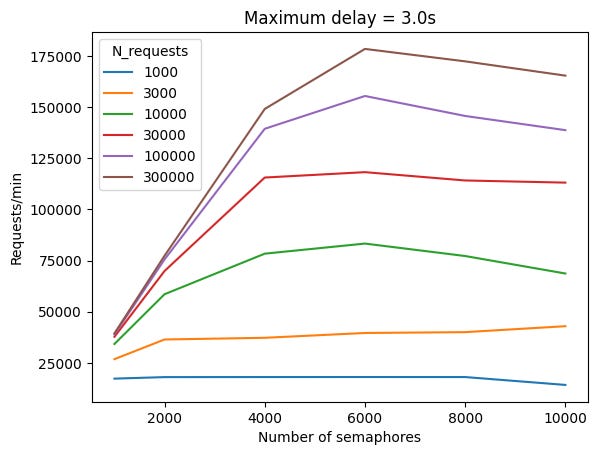
Looking at the figure above, it seems that around 5000 concurrent connections seems to be a sweet spot, at least on my machine. As the number of concurrent increases, we even see signs of the rate of requests decreasing when we try to launch more requests. I kind of suspect it is because the server is no longer able to handle so many concurrent connections in such a short time.
Phase 2: 10 million requests
Using s = 5000, I launched 10 million requests. It took 46.98 mins, averaging 212,842 requests per min! Wow!