

CodeWalkthrough: 10 million requests in Scala with Cats Effect
An exercise on concurrency in Scala using Cats Effect

This is a follow-up from a previous blog post on launching 10 million requests in Python where I reproduced some work on launching asynchronous requests using asyncio and aiohttp.
The purpose of this post is to do the same in Scala by applying the concurrency concepts in the popular Cats Effect library, thus allowing me to get some practical hands-on on the things learnt in my recent Scala journey.
In the end, I managed to launch 10 million requests in around 51 mins. That's around 196k requests per min!
If this interests you, read on…
Experiment Setup
I reused the Python server I used in the previous experiment and launched the requests from Scala.
The request endpoint is very simple. It takes a request ID as a URL parameter and simply returns after some random delay between 0s and 3s. Thus on average, there is a 1.5s delay per request.
Approach
I had to go through a few iterations before I managed to do what I wanted. I will now go through them as I believe that we learn much from our mistakes as well.
As with all my code walkthroughs, I encourage the reader to clone the repository and follow along. I will also include links to the exact code locations so that it is easy to refer to.
First try. Parallel but not concurrent.
My first attempt was to simply use the http4s library and launch the requests using parTraverse. The code lies in the MainParallel.scala file.
This is seen here where the delayed calls are constructed all at once.
val results: IO[List[Unit]] = (1 to 1000).toList.parTraverse(i => call(client, i))Note that the call(client, i) function is the GET request to the server using client as the HTTP client and i as the request ID. parTraverse will construct the calls in parallel and wrap them each in an IO.
Now the problem with this is that while this launches each of the requests in a separate thread, each requests actually blocks the thread that it is on until completion. Control is not yielded to the main program while the request is waiting for the server to return.
Thus I ended up being able to run 24 requests (I have 24 vCPUs on my workstation) in parallel.
1000 requests took around 17s. This equates to around 3500 requests per min. While much faster than running it sequentially, it is still a far cry from the asynchronous request rate seen in the Python experiment.
Second try. Concurrent but runs into OutOfMemory issues.
From the first attempt, it is clear that the slowness is because control is not yielded back to the main program while waiting for the server to respond.
To do so, we need to make use of the Sync[F] typeclass in Cats Effect.
The code for this attempt lies in the MainConcurrent.scala file.
This time round, instead of using http4s, I simply use the SimpleHttpClient in the sttp library to make the GET requests.
As can be seen here, the GET request function is now wrapped in a Sync[IO].blocking function.
def call(client: SimpleHttpClient, id: Int): String = {
val response = client.send(basicRequest.get(uri"http://localhost:8000/$id"))
response.body.getOrElse(s"Failed request: $id")
}
def syncCall(client: SimpleHttpClient, id: Int): IO[String] =
Sync[IO].blocking(call(client, id))The purpose of Sync[IO].blocking is to signify that the call function is a blocking function. Thus it “shifts the evaluation of the effect to a separate threadpool to avoid blocking the compute threadpool. Execution is shifted back to the compute pool once the blocking operation completes” (source: Cats Effect docs).
This means that while the request is waiting, the thread is semantically blocked, and other actions, such as launching more requests, can be conducted by the main program threads.
This is a good improvement. I was able to launch up to 1 million requests in ~5 mins. However, I ran into OutOfMemory errors when I tried to run 10 million requests. On top of that, my workstation was working extremely hard. All 24 cores were almost at 100% utilization (see figure below). This does not seem right.
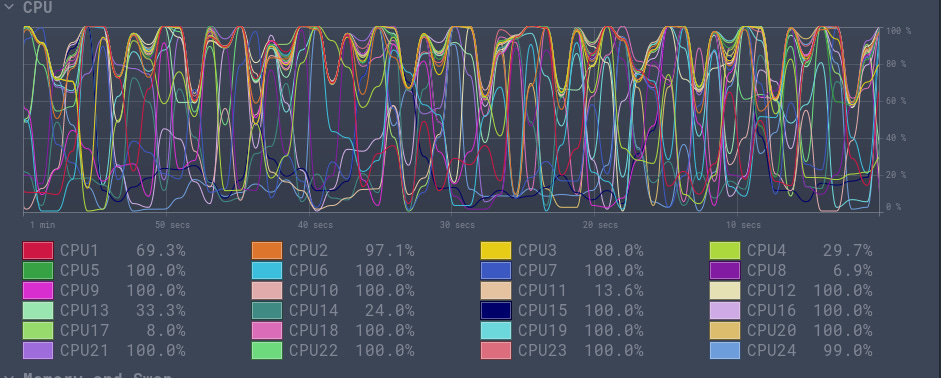
I then realized that the problem lies in the fact that I am scheduling all 10 million requests up front, even though I may not be running them. This is seen in the prog function below.
def prog(client: SimpleHttpClient, maxCalls: Int, sem: Semaphore[IO]): IO[Unit] = {
List.range(0, maxCalls).parTraverse( id => {
for {
_ <- sem.acquire
_ <- syncCall(client, id)
_ <- sem.release
} yield ()
}).as(())
}The List.range(0, maxCalls).parTraverse part basically results in a list of 10 million IOs!
This is why even though I’ve implemented a semaphore to keep the number of requests made concurrently at 5000 (like in the Python experiment), the workstation resource usage still goes crazy.
Third try. Finally, concurrency.
The previous try told me that I had to limit the creation of the delayed GET requests. Thus I implemented a main program function that recursively calls itself only when it is able to obtain a permit from a semaphore.
This is shown by the prog function below. (The code is in MainConcurrent2.scala.)
def prog(client: SimpleHttpClient, maxCalls: Int, sem: Semaphore[IO], tracker: Ref[IO, Int]): IO[Unit] = {
if (maxCalls == 0) then {
IO.unit
} else {
for {
_ <- sem.acquire
fib <- prog(client, maxCalls - 1, sem, tracker).start
resp <- syncCall(client, maxCalls)
_ <- if resp.isSuccess then tracker.update(_ + 1) else IO.unit
_ <- sem.release
_ <- fib.join
} yield ()
}
}The program first tries to acquire a permit from the semaphore. If it is able to, it will first call itself in a separate thread (see the .start call). If not, it will semantically block and not progress until a permit from the semaphore is available.
This means that the program will not try to schedule more calls once all 5000 permits from the semaphore has been used up, thus keeping a lid on the system resources used.
After which, it will make the GET request that is wrapped in a Sync[IO].blocking, which again will free up the compute threads while waiting.
Once the request is made, it will release the permit that it acquired back to the semaphore.
Results from the recursive calls to itself are collected back at the fib.join step.
The figure below shows the resource usage while I was making the 10 million requests. As can be seen, my workstation remained calm and collected.
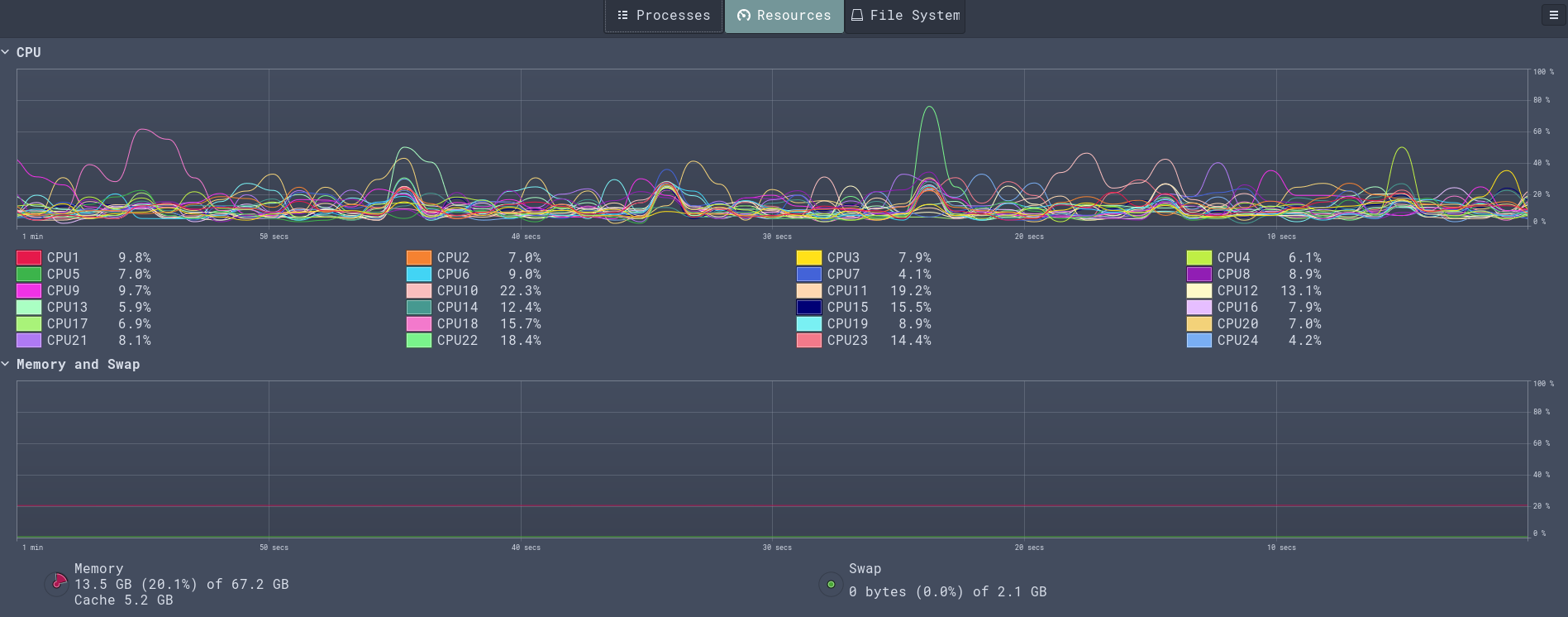
Conclusion
All in all, this was a fun little exercise that helped me solidify my understanding of asynchronous programming in Scala/Cats Effect.
I was also pleasantly surprised that I did not have to manage threadpools or go through callback hell to get all this working.
I hope you enjoyed this!